
Si aún no lo sabes, Scikit Learn es una de las más grandes librerías de Machine Learning con la que cuenta Python, pero no solamente eso, es de las más utilizadas al momento de crear los modelos implementando los algoritmos de Machine Learning, por estas razones es muy importante que aprendas a trabajar con ella si apenas te estás iniciando.
Veamos cómo se puede utilizar esta librería para implementar el algoritmo de Naive Bayes.
Para implementar este algoritmo lo primero que se debe definir es el módulo, sklearn.naive_bayes, e importamos la clase que será GaussianNB. Este módulo cuenta con distintas clases, pero la mencionada acá es la más utilizada de todas.

Una vez que se haya realizado esto se puede implementar este algoritmo en el programa que se este desarrollando. Para realizar el entrenamiento del modelo se utiliza la instrucción fit() junto al algoritmo y para realizar una predicción se utilizar predict() junto al algoritmo. Para aplicar ambas instrucciones se deberá haber definido previamente las variables independientes y dependiente para poderlas utilizar acá. Este es el mismo procedimiento que se ha utilizado con los otros algoritmos de Machine Learning que se han explicado.
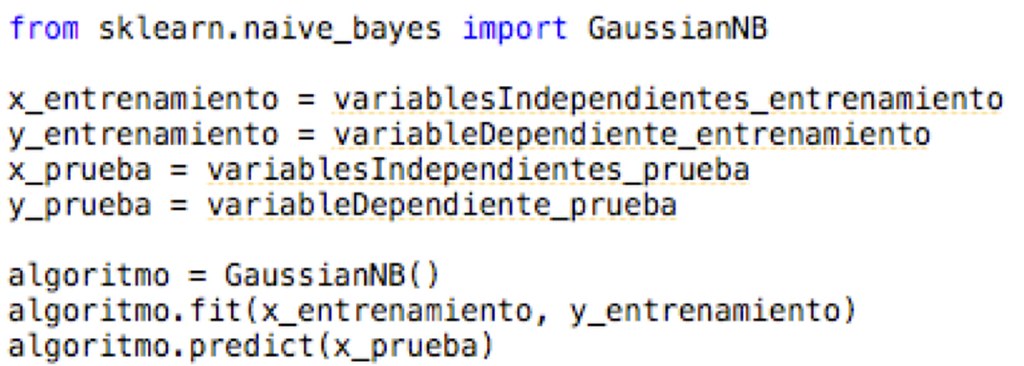

Este algoritmo por ser muy básico no requiere de mucha configuración de parámetros, inclusive solamente cuenta con tan solo dos parámetros, que por lo general no se utilizan. En otras palabras, al implementar este algoritmo se deja tal cual como está sin realizar ninguna configuración de los parámetros.


Si hacemos un resumen de los comandos para implementar el algoritmo de Naive Bayes son los siguientes:




Como podemos observar nos indica que el dataset cuenta con la siguiente información: primeramente “data”, que serían los datos independientes, seguidamente “target”, correspondiente a la columna con las etiquetas o respuestas, posteriormente tenemos “target_names” que son los nombres de las variables que se encuentran en la columna de “target”, después tenemos “DESCR” que sería la descripción total del dataset y finalmente tenemos “features_names” correspondiente a los nombres de cada una de las columnas de los datos.
Ya sabiendo todo esto podemos utilizar cada uno de estos nombres para entender mejor los datos, lo primero que vamos hacer es utilizar “DESCR” para conocer las características del dataset.
Aplicado el respectivo comando, podemos verificar que el dataset cuenta con 569 datos y un total de 30 atributos, todos ellos numéricos.

Algunos de los atributos o variables independientes son: el radio, la textura, el perímetro y el área, recuerda que acá vamos a predecir si un paciente tiene cáncer o no, para ello debemos conocer todas las características del tumor para determinar con ella si el tumor es maligno o benigno.

Podemos observar que de cada una de estas variables tenemos la información de la media, el error estándar y el peor, que vendría siendo la media de los tres valores más grandes.
Toda esta información hace los 30 atributos que en total cuenta este dataset.
Otro dato importante que nos proporciona esta información es que no existe ningún atributo perdido por lo que el dataset está completo haciendo que no sea necesario el preprocesamiento de los datos, para completar con datos perdidos.

Finalmente nos indica que en estos datos 212 son tumores malignos mientras que 357 son benignos, esto nos indica que los datos se encuentran balanceados por lo que no nos tenemos que preocupar por trabajar con un dataset desbalanceado.
Con esta información considero que ya tenemos más claro el dataset con el que estamos trabajando. En caso de que quieras profundizar en alguna información adicional puedes utilizar cualquiera de las otras instrucciones que he explicado en anteriores videos.
Ahora vamos a proceder a definir las variables de “X” y “y” que vamos emplear en nuestro modelo.



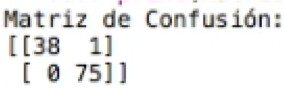
El resultado acá, es que tenemos 113 datos predichos correctamente y 1 dato erróneo obtenido luego de realizar la predicción.
Viendo este resultado podemos concluir que el modelo predijo la gran mayoría de los datos por lo que es un buen modelo que podemos utilizar.
Ahora veamos la precisión del mismo, para esto importamos precision_score del módulo sklearn.metrics y lo implementamos de igual forma junto a los datos de entrenamiento y los predichos.

El resultado obtenido acá es de 0,986. Por lo que consideramos que el modelo cumple con su función.







