
Si aún no lo sabes, Scikit Learn es una de las más grandes librerías de Machine Learning con la que cuenta Python, pero no solamente eso, es de las más utilizadas al momento de crear los modelos implementando los algoritmos de Machine Learning, por estas razones es muy importante que aprendas a trabajar con ella si apenas te estás iniciando.
Veamos cómo se puede utilizar esta librería para implementar el algoritmo de Vectores de Soporte Regresión.
El objetivo de los Vectores de Soporte Regresión es la de individualizar el hiperplano maximizando el margen, teniendo en cuenta que se tolera parte del error.
Lo primero que debes saber es que Scikit Learn cuenta con un módulo llamado sklearn.svm en donde se incluye todo lo referente al algoritmo de Vectores de Soporte tanto clasificación como regresión. Para esta publicación nos enfocaremos solamente en regresión y más específicamente en SVR.

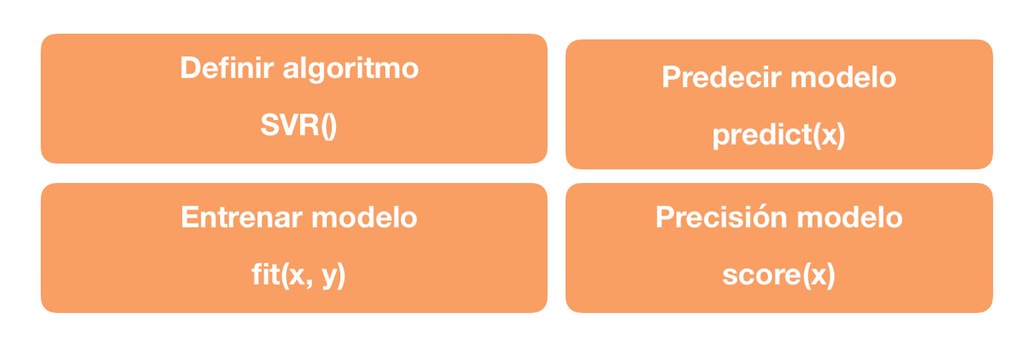
Con Scikit Learn es extremadamente sencillo implementar este algoritmo, lo primero que debemos hacer es importar el módulo e importar la clase SVR, crear los parámetros a utilizar, “x” y “y” y llamar al método fit() junto con los datos de entrenamiento.


La instrucción SVR se puede configurar con ciertos parámetros que puedes ver en la página web con más detalle, acá te voy a explicar los más importantes y los que debes considerar al momento de configurar el modelo.

Comencemos con C, te acuerdas que cuando vimos la teoría del algoritmo de vectores de soporte regresión, en la fórmula se disponía de una variable llamada C, la cual la definimos como una constante que determina el equilibrio entre la regularidad de la función y la cuantía hasta la cual toleramos desviaciones mayores que las bandas de soporte, bueno este valor lo puedes definir acá, por defecto este valor es de 1 pero tu lo puedes definir a tu conveniencia.

Otro parámetro que puedes modificar es el de “épsilon”,
Ambas variables las puedes modificar a tu conveniencia, pero tradicionalmente esto valores se dejan por defecto, sobretodo si apenas estas empezando en Machine Learning y no tienes la suficiente destreza para manipularlos.
Una configuración que cuenta este algoritmo en Scikit Learn y que en ocasiones si se modifica es la de Kernel, pero hasta los momentos no he explicado mucho al respecto, por lo que acá solamente la voy a nombrar y más adelante habrá un video dedicado completamente a explicar de qué se trata los Kernel y porque son bastante útiles sobretodo para este tipo de algoritmos.
Por los momentos me voy a limitar a decir que acá se puede definir uno de los tres tipos de Kernel que se manejan, lineal, que se utiliza cuando los datos son lineales, y para los datos no lineales se cuenta con “poly”, “rbf” y “sigmoid”. Si este parámetro no se configura al momento de utilizar este algoritmo, se utilizará “rbf” como Kernel por defecto.
Recuerda que estos son solo algunos de los parámetros que cuenta este algoritmo para su configuración.


En resumen, los comandos a utilizar para implementar un algoritmo de Regresión Lineal serían los siguientes:




Como puedes observar el conjunto de datos cuenta con la siguiente información: primeramente, la data, seguidamente target que sería la columna con las etiquetas o respuestas, posteriormente tenemos feature_names que serían los nombres de cada una de las columnas de la data y finalmente tenemos DESCR que sería la descripción total del dataset.
Sabiendo ya esto podemos ahora utilizar estos nombres para entender mejor los datos, lo primero que vamos a hacer es utilizar DESCR para ver las características del dataset.

Como ya nos lo visto anteriormente este conjunto de datos cuenta con 506 muestras y 13 columnas.
Finalmente veamos las etiquetas de cada columna para ello utilizamos feature_names.

Sabiendo toda esta información entonces procedemos a preparar los datos que vamos a utilizar para crear el modelo.


Como podemos observar estos datos tienen un comportamiento lineal, por lo que acá implementaremos el algoritmo de Vectores de Soporte Regresión, con un kernel línea, de la misma forma que lo explicamos en la teoría.
Procedemos ahora a separar los datos en entrenamiento y prueba, para ello utilizamos la instrucción train_test_split.


Cómo definimos, al momento de configurar el algoritmo, el kernel que estamos utilizando es lineal por lo que el modelo es una línea, la cual va a tratar de cubrir la mayor cantidad de datos. Pero si observamos acá la línea acá tiene un comportamiento similar a los datos de entrenamiento.
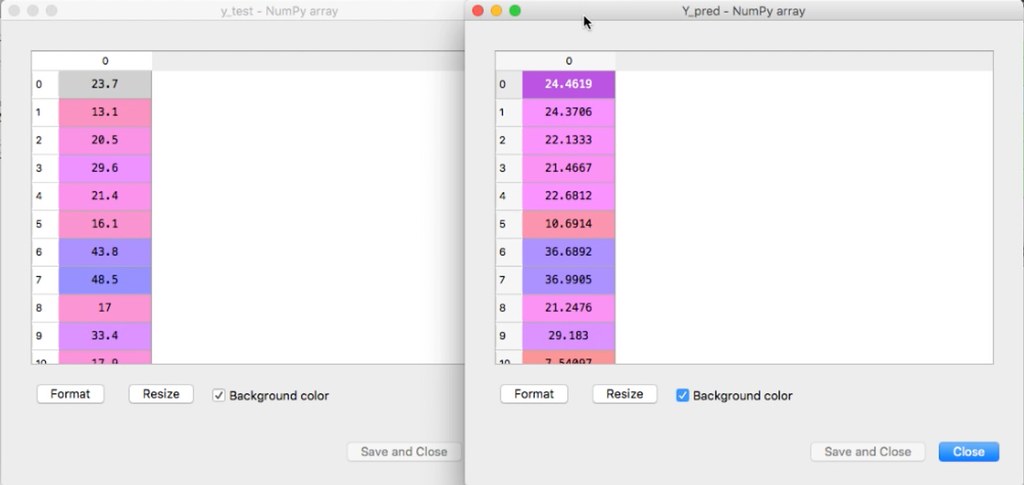


Como ya lo habíamos visto comparando los resultados de “y_predict” podríamos deducir que la precisión no iba a ser muy buena. Recuerda que mientras este valor sea más cercano a 1 mejor será nuestro modelo.








Hola, tengo una pregunta en cuanto al visualizar esta regresión, y es si hay alguna forma de poder visualizar las líneas de vectores de soporte. No he encontrado nada al respecto, solo con SVC, pero no puedo hacerlo en SVR. Gracias de antemano.
Hola Javier, si lo puedes hacer pero tienes que realizarlo utilizando programación tradicional de Python. Saludos.
Hola! Muy buenos tus videos.
Yo uso Databricks, y me gustaria saber si existe alguna forma de comparar los valores obtenidos en nuestra predicción con los valores reales, para ver que tal es el comportamiento del modelo creado. Por lo que he visto, tú lo haces en Spyder. Pero me gustaria saber si puedo visualizar al menos algunos datos del y_test y compararlos con su valor correspondiente en y_predict.
Gracias por todo, excelente contenido, de gran ayuda.
Saludos,
Valentín Lorbeer.
Hola Valentin, como te lo comento en tu comentario de YT, no utilizo Databricks, pero yo diría que si es posible hacer lo que estás explicando acá. Saludos.