

Los datos lo vamos a obtener de la página de Kaggle, para ello se deben suscribir para poder tener acceso a los mismos, aunque este dataset está también disponible en el repositorio de la Universidad de California, lugar en donde originalmente se publicaron estos datos.
Igual que en los anteriores programas vamos a utilizar como lenguaje de programación Python.

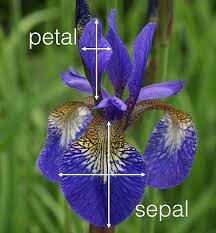
Antes de empezar a programar entendamos un poco este dataset. Este conjunto de datos contiene 50 muestras de cada una de tres especies de Iris: Iris setosa, Iris virginica e Iris versicolor, para cada una de estas especies se midieron cuatro rasgos de cada muestra: la longitud y el ancho del sépalos y pétalos. Los sépalos son los que envuelven a las otras piezas florales en las primeras fases de desarrollo, cuando la flor es solo un capullo, por su parte los pétalos son la parte inferior del perianto y comprende las partes estériles de una flor.
En estas fotos podrás observar la diferencia entre pétalo y sépalo y a su vez la diferencia entre las tres especies de Iris.
Sabiendo todo esto ahora si podemos empezar a programar.



Como podemos observar el dataset cuenta 6 columnas, en donde están las características de ancho y longitud del sépalo y pétalo, a su vez el nombre de cada una de las especies. Pero adicionalmente a todo esto se encuentra una columna llamada ID que está demás, ya que una vez que los datos se convierten en pandas se crea automáticamente una columna con la numeración por lo que podemos eliminar la columna ID. Para esto utilizamos la instrucción drop.

Ahora procedemos a analizar los datos. Acá utilizamos todos los comandos necesarios para entender el dataset.
Primeramente, utilizaremos info.
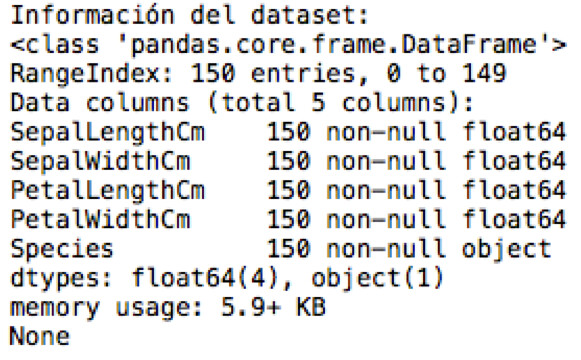
Acá nos indica que todas las columnas contienen 150 datos, en las primeras tenemos datos flotantes mientras que la última contiene datos objetos y es justamente acá en donde se encuentra la información de las especies de la flor.
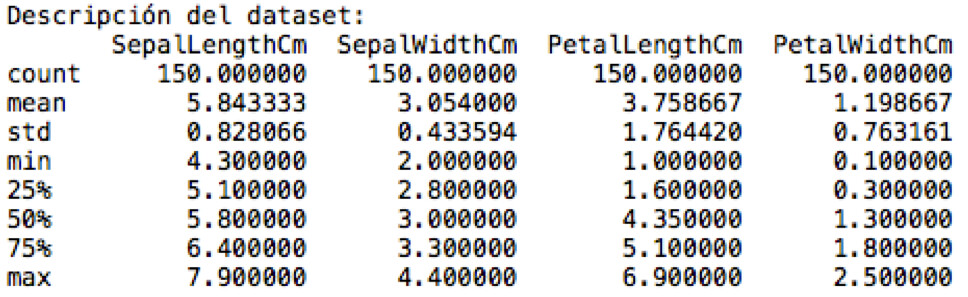
Seguidamente utilizamos describe. En donde podemos observar los datos estadísticos del dataset.
Por último, verificamos la distribución de los datos de acuerdo a las especies de Iris, para ello utilizamos la instrucción groupby, especificando la columna Species y el tamaño de la misma.

Como podemos observar tenemos 50 datos para cada una de las especies, Iris setosa, Iris versicolor e Iris Virginica.

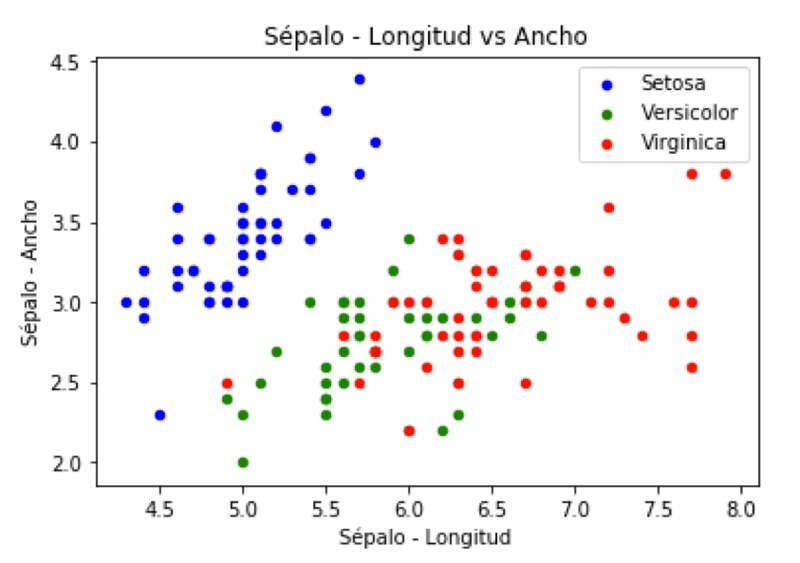
Si te fijas en la gráfica los datos están distribuidos de manera casi uniforme sobretodo los correspondientes al Iris setosa, mientras que los correspondientes a versicolor y virginica tienen cualidades algo parecidas por lo que se solapan en ocasiones.
Ahora procedemos a hacer exactamente lo mismo, pero con la información de los pétalos. Si te fijas el código de programación es exactamente el mismo al anterior lo único diferente es que ahora se especifica los datos del pétalo.

![]()
Ahora si empecemos a aplicar los algoritmos de Machine Learning comenzando con Regresión Logística. Obviamente lo primero que debemos hacer es definir el algoritmo, LogisticRegression, seguidamente lo entrenamos utilizando la instrucción fit y realizamos la una predicción utilizando los datos de X_test. Para determinar la precisión o confianza del algoritmo utilizamos la instrucción score para calcularla.
![]()
Con ella nos da un resultado de 0,975, lo cual no esta nada mal pero aún así vamos a verificar con otros algoritmos para ver si mejoramos este número.
Procedemos a desarrollar un nuevo modelo ahora con el algoritmo de Máquinas de Vectores de Soporte, el procedimiento es exactamente igual, primero definimos el algoritmo, en este caso será SVC, lo entrenamos utilizando los datos de entrenamiento, realizamos una predicción y finalmente calculamos la precisión del mismo.
![]()
Acá el resultado es igual a 1, es decir que se puede decir que este modelo es perfecto, por lo que sería el ideal para realizar las próximas predicciones.
Con esto tenemos un modelo creado con todo el conjunto de datos, ahora vamos a desarrollar y evaluar un nuevo modelo pero esta vez solamente con los datos correspondientes al sépalo, es decir que este modelo solamente evaluara estos datos más no los del pétalo.
El procedimiento es muy parecido al anterior la diferencia son los datos que tomares para construir el modelo, entonces empecemos el desarrollo.
Lo primero es definir los datos, como son exclusivamente los del sépalo debemos seleccionar estas columnas, que sería el de la longitud y ancho del sépalo y obviamente la columna correspondiente a la de especies.
![]()
La precisión de este modelo es de 0,75 lo que cual no es tan bueno, por lo que tenemos que evaluar otros algoritmos para verificar si podemos obtener algo mejor.
Por lo tanto, ahora desarrollemos un modelo utilizando el algoritmo de Máquinas de Vectores de Soporte, igual que anteriormente, definimos el algoritmo, lo entrenamos, realizamos una predicción y finalmente calculamos la precisión.
![]()
El resultado es de 0,941, siendo este el mejor de los resultados por lo que este es el mejor modelo de todos.
Ahora desarrollemos el último de los modelos que vamos hacer en este proyecto, para este vamos a utilizar los datos correspondientes al pétalo, tanto longitud como ancho y por supuesto la columna de especies que sería la etiqueta.
El procedimiento acá es exactamente igual al anterior, la única diferencia son los datos que vamos a tomar para entrenar el modelo, entonces empecemos con este desarrollo.
Lo primero que debemos hacer es definir las columnas con las que vamos a trabajar, como ya lo indicamos son las correspondientes al pétalo.
![]()
Con esto ya podemos realizar las pruebas respectivas con cada uno de los algoritmos igual que lo hicimos anteriormente.
Comencemos con el algoritmo de Regresión Logística.
![]()
Con este algoritmo obtenemos 0,891, que no es un buen resultado, por lo que debemos continuar con las pruebas.
Ahora desarrollamos el algoritmo de Máquinas de Vectores de Soporte.







Muchas gracias por los aportes en PYTHON
Gracias a ti por comentar.
Segui todo tu codigo esta increible,, gracias enseñarnos.
Tienes algun codigo de entranamiento de Red Neuronal con Keras?.
Saludos..
Hola Manuel, muchas gracias por tu comentario. Por los momentos no tengo nada de redes neuronales pero si tengo planificado generar contenido al respecto. Saludos.
Magnifico, para el aprendizaje, muchas gracias, has compartido un compendio pedagógico muy claro, sencillo y directo.
Hola Reinan, muchas gracias por tu comentario y tus palabras. Saludos.
Hola! muchas gracias, excelente explicación. Mi pregunta es: luego que tengo definido mi modelo (en este caso el de arboles de decisión, por tener la mejor precisión) como aplico luego el modelo en un conjunto de datos de valores de sépalo y pétalo para determinar que tipo de iris es?
Hola Carol, solamente tienes que ingresarle los nuevos datos con el mismo orden y formato que hiciste en las pruebas. Saludos.
Veo un error, Para calcular el Score del algoritmo deberías haber usado los datos de test, asi: algoritmo.score(X_test, y_test) en lugar de algoritmo.score(X_train, y_train)
Hola Javier, puedes utilizar tanto test como train, inclusive es bueno utilizar ambas para determinar si hay un sobreajuste en el modelo. Recuerda que acá yo te doy las bases queda de tu parte que mejores el proyecto. Saludos.
Hola me sale un error al importar en esta parte
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
AttributeError: module ‘scipy’ has no attribute ‘_lib’
Hola Anderson, trata de actualizar la librería de repente ese sea el problema. Saludos.
Esta muy buena la información, somo seria podrías ayudarme con un clasificador de iris según datos ingresados al azar, yque este programa indique según una @data a que tipo de iris pertenece.
Hola Yordi, puedes utilizar como base este programa para realizar lo que me planteas acá. Saludos.
Muchas gracias por la información, fue de mucha utilidad y de fácil comprensión. Una apreciación, en la instrucción para regresión logística solo de sépalo del ejercicio del blog para: Ahora procedemos a separar los datos de entrenamiento y prueba para proceder a construir los modelos.
#Separo los datos de «train» en entrenamiento y prueba para probar los algoritmos
X_train_s, X_test_s, y_train_s, y_test_s = train_test_split(X_sepalo, y_sepalo, test_size=0.2)
print(‘Son {} datos sépalo para entrenamiento y {} datos sépalo para prueba’.format(X_train.shape[0], X_test.shape[0]))
En la línea de abajo, en la parte de: X_train.shape[0], X_test.shape[0])) creo que debería ser: X_train_s.shape[0], X_test_s.shape[0]))
Sino arroja error.
Hola Zamy, tienes razón. Muchas gracias por la corrección. Saludos.
Hola! Se podría entrenar con un perceptrón?
Hola Lourdes, si claro lo puedes entrenar. Saludos.
Esto esta genial , Muchas gracias ojalá mi profesor explicara así.
Hola José, muchas gracias por las palabras. Saludos.
Los scores del código son sobre los subset de entrenamiento; en realidad lo significativo es ver el desempeño del modelo entrenado con los subsets de test.
Ejemplo
print(
«Model score: %f»
% algoritmo.fit(X_train, y_train).score(X_test, y_test))
Un saludo y felicitaciones por el aporte.
Excelente. Muchas gracias! Fue muy fácil aprender a clasificar y con este dataset. Conoci como obtener otros dataset para seguir con el tema.