



Como podemos observar nos indica que el dataset cuenta con la siguiente información: primeramente “data”, que serían los datos independientes, seguidamente “target”, correspondiente a la columna con las etiquetas o respuestas, posteriormente tenemos “target_names” que son los nombres de las variables que se encuentran en la columna de “target”, después tenemos “DESCR” que sería la descripción total del dataset y finalmente tenemos “features_names” correspondiente a los nombres de cada una de las columnas de los datos.
Ya sabiendo todo esto podemos utilizar cada uno de estos nombres para entender mejor los datos, lo primero que vamos hacer es utilizar “DESCR” para conocer las características del dataset.
Aplicado el respectivo comando, podemos verificar que el dataset cuenta con 569 datos y un total de 30 atributos, todos ellos numéricos.

Algunos de los atributos o variables independientes son: el radio, la textura, el perímetro y el área, recuerda que acá vamos a predecir si un paciente tiene cáncer o no, para ello debemos conocer todas las características del tumor para determinar con ella si el tumor es maligno o benigno.

Podemos observar que de cada una de estas variables tenemos la información de la media, el error estándar y el peor, que vendría siendo la media de los tres valores más grandes.
Toda esta información hace los 30 atributos que en total cuenta este dataset.
Otro dato importante que nos proporciona esta información es que no existe ningún atributo perdido por lo que el dataset está completo haciendo que no sea necesario el preprocesamiento de los datos, para completar con datos perdidos.

Finalmente nos indica que en estos datos 212 son tumores malignos mientras que 357 son benignos, esto nos indica que los datos se encuentran balanceados por lo que no nos tenemos que preocupar por trabajar con un dataset desbalanceado.
Con esta información considero que ya tenemos más claro el dataset con el que estamos trabajando. En caso de que quieras profundizar en alguna información adicional puedes utilizar cualquiera de las otras instrucciones que he explicado en anteriores videos.
Ahora vamos a proceder a definir las variables de “X” y “y” que vamos emplear en nuestro modelo.



Si comparamos los datos que predecimos con los datos reales podemos ver que nuestro modelo realizo un excelente trabajo ya que a simple vista podemos observar que los datos predichos son exactamente igual a los datos reales.
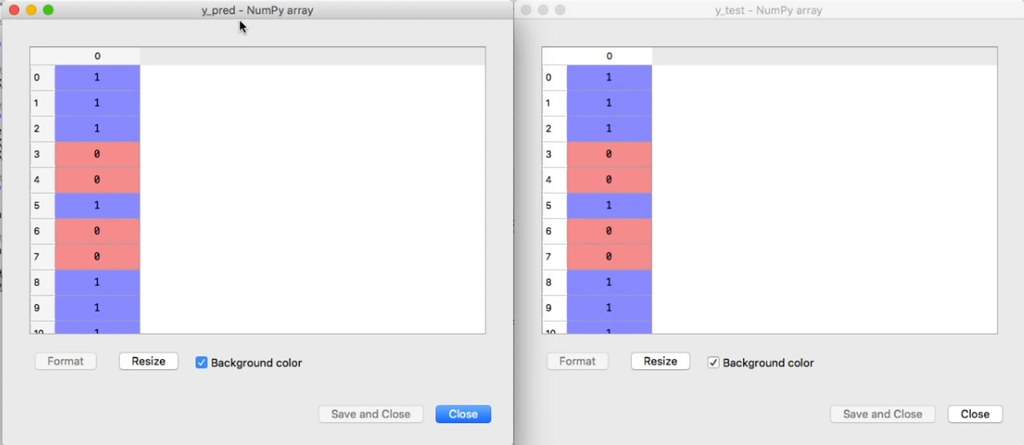
Los datos predichos son los ubicados en la tabla de lado izquierdo mientras que los originales se encuentran en el lado derecho.
Pero veamos si esto es cierto, para ello calculamos las métricas respectivas para verificar el rendimiento del modelo. Para esto debemos primero obtener la matriz de confusión utilizando la librería metrics de scikit learn y el módulo confusion-matrix.

El resultado de la precisión es de 0,959.
Esto coincide con lo que vimos en la matriz de confusión, demostrando que nuestro modelo es bastante bueno.
Calculemos ahora la exactitud del modelo, por lo que debemos ahora importar accuracy_score, de la misma librería de metrics.

Aplicamos este comando a los datos de pruebas y obtenemos una exactitud de 0,964, valor muy parecido al anterior.
Veamos ahora la sensibilidad o lo que también se le conoce como recall del algoritmo, para ello importamos recall_score.

Implementando esta métrica obtenemos una sensibilidad del 0,986.
Calculemos ahora el puntaje F1 que es una combinación entre la precisión y la sensibilidad, para esto importamos f1_score.

Realizado esto procedemos a implementar la instrucción junto a los datos calculados del modelo, obteniendo 0,972.
Finalmente, la curva ROC – ACU del modelo, para ello importamos roc_auc_score. Recuerda que todas estas instrucciones se encuentran dentro de la librería scikit-learn dentro de metrics.
![]()
Aclarado esto implementamos el comando junto con los datos respectivos y obtenemos 0,957.
Verificando todos los datos obtenidos vemos que son similares unos y otros.
Recuerda que no es necesario hacer todos estos cálculos porque nuestros datos se encuentran balanceados, los hago acá para que vean cómo se pueden obtener.








POR QUE UTILIZA LA PREDICION PARA CALCULAR roc_auc , Y NO UTILIZA LA PREDIC_PROBA ?
DEBERIA UTILIZAR PREDIC_PROBA
roc_auc = roc_auc_score(y_test, y_pred)
print(‘Curva ROC – AUC del modelo:’)
print(roc_auc)