
El algoritmo KNN es uno de los algoritmos de clasificación más simples, incluso con tal simplicidad puede dar resultados altamente competitivos. Pertenece al dominio de aprendizaje supervisado y puede ser utilizado para el reconocimiento de patrones, extracción de datos y detección de intrusos.
Es un clasificador robusto y versátil que a menudo se usa como un punto de referencia para clasificadores más complejos como las redes neuronales artificiales y vectores de soporte (SVM). A pesar de su simplicidad, KNN puede superar a los clasificadores más potentes y se usa en una variedad de aplicaciones tales como pronósticos económicos, compresión de datos y genética.
Este algoritmo consiste en seleccionar un valor de K. Al momento del análisis los K datos más cercanos al valor que se desea predecir será la solución.
Acá lo importante es seleccionar un valor de K acorde a los datos para tener una mayor precisión en la predicción.

El clasificador KNN, por sus siglas en inglés, es también un algoritmo de aprendizaje no paramétrico y basado en instancias:
- No paramétrico significa que no hace suposiciones explícitas sobre la forma funcional de los datos, evitando modelas mal la distribución subyacente de los datos. Por ejemplo, supongamos que nuestros datos son altamente no gaussianos, pero el modelo de Machine Learning que elegimos asume una forma gaussiana. En este caso, nuestro algoritmo haría predicciones extremadamente pobres.
- El aprendizaje basado en la instancia significa que nuestro algoritmo no aprende explícitamente un modelo. En lugar de ello, opta por memorizar las instancias de formación que posteriormente se utilizan como “conocimiento” para la fase de predicción. Concretamente, esto significa que solo cuando se realiza una consulta a nuestra base de datos, es decir, cuando le pedimos que predique una etiqueta con una entrada, el algoritmo utilizará las instancias de formación para dar una respuesta.
Cabe señalar que la fase de formación mínima de KNN se realiza tanto a un coste de memoria, ya que debemos almacenar un conjunto de datos potencialmente enorme, como un coste computacional durante el tiempo de prueba, ya que la clasificación de una observación determinada requiere un agotamiento de todo el conjunto de dato. En la práctica, esto no es deseable, ya que normalmente queremos respuestas rápidas.

Supongamos que Z es el punto el cual se necesita predecir. Primero, se encuentra el punto K más cercano a Z y luego se clasifican los puntos para el voto mayoritario de sus vecinos K. Cada objeto vota por su clase y la clase con más votos se toma como la predicción. Para encontrar los puntos similares más cercanos, se encuentra la distancia entre puntos utilizando medidas de distancias.

Una opción popular es la distancia euclidiana, pero también hay otras medidas que pueden ser más adecuadas para un entorno dado e incluyen la distancia de Mahattan y Minkowski.
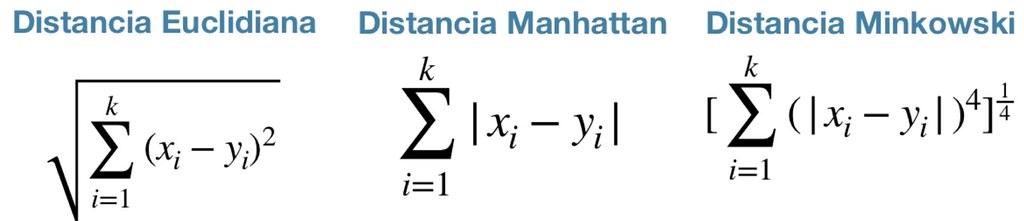
En resumen, KNN tiene los siguientes pasos básicos:
- Calcular la distancia
- Encontrar sus vecinos más cercanos
- Votar por las etiquetas











Muchas gracias. Justo andaba buscando una explicación sencilla y rápida de este algoritmo para mis estudiantes.
Me alegra Rafael, espero que te haya ayudado. Saludos.