Antes de empezar a explicar de qué se trata el Clustering, veamos un ejemplo.
Un banco quiere dar ofertas de tarjetas de crédito a sus clientes. En la actualidad, examinan los detalles de cada cliente y, basándose en esta información, deciden qué oferta se debe hacer a qué cliente.
Ahora, el banco puede tener potencialmente millones de clientes, por lo que ¿tiene sentido mirar los detalles de cada cliente por separado y luego tomar una decisión? Por supuesto que no. Este sería un proceso manual y tomaría una gran cantidad de tiempo.
Por lo tanto, ¿qué puede hacer el banco? Una opción es segmentar a sus clientes en diferentes grupos, por ejemplo, el banco puede agrupar a los clientes en función de sus ingresos: ingresos altos, ingresos promedios, ingresos bajos.
El banco puede ahora hacer tres estrategias u ofertas diferentes, una para cada grupo. Aquí, en lugar de crear estrategias diferentes para clientes individuales, solo tienen que hacer 3 estrategias. Esto reducirá el esfuerzo, así como el tiempo.
Los tres grupos formados se le conocen como clústeres y el proceso de creación de estos grupos se conoce clustering.
Formalmente, podemos decir que la agrupación en clústeres el proceso de dividir todos los datos en grupos, también conocidos como clústeres, basados en los patrones de los datos.
El Clustering o agrupamiento es una de las formas de Aprendizaje no Supervisado más utilizada. Es una gran herramienta para dar sentido a los datos no etiquetados y para agrupar datos en grupos similares.
Un algoritmo de agrupamiento puede descifrar estructuras y patrones en un conjunto de datos que no son aparentes para el ojo humanos. En general, la agrupación en clúster es una herramienta muy útil para añadir a su conjunto de herramientas de Machine Learning.
¿Qué es un clúster?
Clúster es la colección de objetos de datos que son similares entre sí dentro del mismo grupo, clase o categoría y son diferentes de los objetos de los otros clústeres.
La agrupación es una técnica de Aprendizaje no Supervisada en la que hay clases predefinidas e información previa que define cómo se deben agrupar o etiquetar los datos en clases separadas. También podría considerarse como un proceso de análisis exploratorio de datos que nos ayuda a descubrir patrones ocultos de interés o estructura en los datos.
La agrupación en clúster también puede funcionar como una herramienta independiente para obtener información sobre la distribución de datos o como un paso de preprocesamiento en otros algoritmos.
Propiedades de los clústeres
Tomemos el mismo ejemplo del banco, mencionado anteriormente. Por razones de simplicidad, digamos que el banco solo quiere utilizar los ingresos y la deuda para hacer la segmentación. Recolectaron los datos de los clientes y usaron un gráfico de dispersión para visualizarlos:
En el eje X, tenemos los ingresos del cliente y el eje Y representa el monto de la deuda. Aquí, podemos visualizar claramente que estos clientes pueden ser segmentados en 4 grupos diferentes.
Así es como el clustering ayuda a crear segmentos o clústeres a partir de los datos. Además, el banco puede utilizar estos clústeres para elaborar estrategias y ofrecer descuentos a sus clientes. Así que veamos las propiedades de estos grupos.
Propiedad 1
Todos los puntos de datos de un clúster deben ser similares entre sí. Veamos esto en nuestro ejemplo.
Si los clientes de un grupo particular no son similares entre sí, entonces sus necesidades pueden variar. Si el banco les hace la misma oferta, es posible que no le guste y que su interés en el banco se reduzca, por lo que no es lo ideal.
Tener puntos de datos similares dentro del mismo clúster ayuda al banco a utilizar el marketing dirigido. Puedes pensar en ejemplos similares de tu vida diaria y pensar en cómo los clústeres impactarán o ya impactan la estrategia de negocio.
Propiedad 2
Los puntos de datos de los diferentes grupos deben ser lo más diferentes posibles. Esto tendrá sentido intuitivamente si captaste la propiedad anterior. Tomemos de nuevo el mismo ejemplo para entender esta propiedad. ¿Cuál de estos casos crees que nos dará los mejores grupos?
Si miras el caso 1, los clientes de los grupos verde y azul son muy similares entre sí. Los tres primeros puntos del grupo verde comparten propiedades similares a las de los dos primeros clientes del grupo azul. Tienen altos ingresos y un alto valor de deuda. Aquí los hemos agrupado de manera diferente.
Mientras que, si miras el caso 2, los puntos del grupo verde son completamente diferentes de los clientes del grupo azul. Todos los clientes del clúster azul tienen ingresos altos y deudas altas, y los clientes del clúster verde tienen ingresos altos y un valor de deuda bajo. Claramente tenemos una mejor agrupación de clientes en este caso.
Por lo tanto, los puntos de datos de diferentes conglomerados deben ser tan diferentes entre sí como sea posible para tener clustering más significativos.
Clasificación vs. Clustering
Entendamos cómo la clasificación en el Aprendizaje Supervisado es diferente del clustering en el Aprendizaje no Supervisado.
Clasificación
En el Aprendizaje Supervisado nuestro modelo aprende un método para predecir la clase de instancia a partir de una instancia preetiquetada o clasificada.
Clustering
En el Aprendizaje no Supervisado, nuestro modelo trata de encontrar una agrupación natural de instancias para un dato dado sin etiquetar.
¿Cómo definimos los buenos algoritmos de clustering?
Se pueden crear clústeres de alta calidad reduciendo la distancia entre los objetos en el mismo clúster conocido como minimizando intraclúster y aumentando la distancia con los objetos en el otro clúster conocido como maximización interclúster.
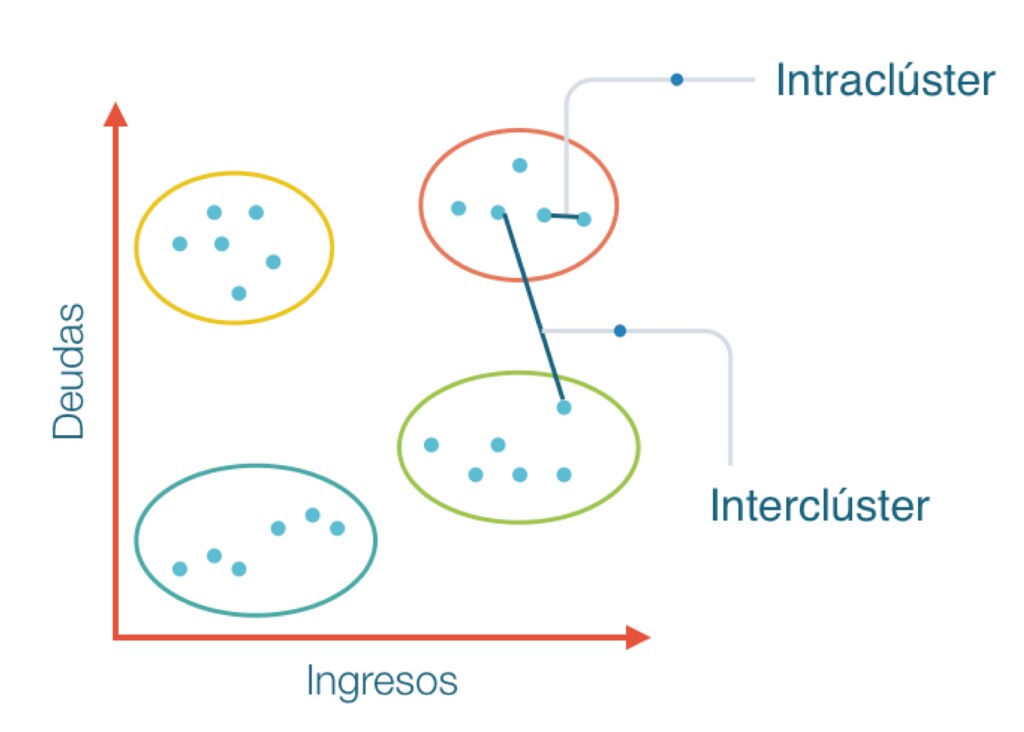
Minimización intraclúster: cuanto más cerca estén los objetos de un grupo, más probable es que pertenezcan al mismo grupo.
Maximización interclúster: esto hace la separación entre dos grupos. El objetivo principal es maximizar la distancia entre dos clústeres.
Métricas de Evaluación
El objetivo principal del clustering no es solo crear agrupaciones, sino también crear agrupaciones buenas y significativas, lo vimos en el ejemplo anterior.
Aquí, usamos solo dos características y por lo tanto fue fácil para nosotros visualizar y decidir cuál de estos clústeres es mejor.
Desafortunadamente, así no es como funcionan los escenarios del mundo real. Tendremos un montón de características con las que trabajar.
Tomemos de nuevo el ejemplo de segmentación de clientes del banco, tendremos características como los ingresos, la ocupación, el sexo, la edad y muchas más. Visualizar todas estas características juntas y decidir mejores y más significativos clústeres no sería posible para nosotros.
Aquí es donde podemos hacer uso de las métricas de evaluación. Discutamos algunos de ellos y entendamos cómo podemos usarlos para evaluar la calidad de nuestros clústeres.
Inercia
Recuerdas la primera propiedad de los grupos que cubrimos anteriormente. Esto es lo que evalúa la inercia. Nos dice cuán lejos están los puntos dentro de un grupo. Entonces, la inercia realmente calcula la suma de todos los puntos dentro de un cúmulo a partir del centroide de ese cúmulo.
Calculamos esto para todos los clústeres y el valor inercia final es la suma de todas estas distancias. Esta distancia dentro los clústeres se conoce como distancia intraclústeres. Entonces, la inercia nos da la suma de las distancias intraclústeres.
Ahora, ¿cuál crees que debería ser el valor de la inercia para un buen grupo? ¿es bueno un valor inicial pequeño o necesitamos un valor mayor? Queremos que los puntos dentro del mismo grupo sean similares entre sí, por lo tanto, la distancia entre ellos debe ser lo más baja posible.
Teniendo esto en cuenta, podemos decir que cuanto menor es el valor de inercia, mejores son nuestros clústeres.
Índice Dunn
Ahora sabemos que la inercia trata de minimizar la distancia intraclústeres, tratando de hacer grupos más compactos. Si la distancia entre el centroide de un clúster y los puntos de ese clúster es pequeña, significa que los puntos están más cerca unos de otros. Por lo tanto, la inercia se asegura de que se satisfaga la primera propiedad de los clústeres. Pero no le importa la segunda propiedad, que los distintos grupos sean lo más diferentes posible.
Aquí es donde el índice Dunn puede entrar en acción.
Junto con la distancia entre el centroide y los puntos, el índice Dunn también tiene en cuenta la distancia entre dos grupos. Esta distancia entre los centros de dos clústeres diferentes se conoce como interclústeres. Veamos la fórmula del índice Dunn:

El índice Dunn es la relación entre el mínimo de distancia entre clúster y el máximo de distancias entre clúster.
Queremos maximizar el índice Dunn. Cuanto más el valor del índice Dunn, mejor serán los clústeres.
Entendamos la intuición detrás del índice de Dunn:
- Para maximizar el valor del índice Dunn, el numerador debe ser máximo. Aquí, estamos tomando el mínimo de las distancias entre los clústeres. Por lo tanto, la distancia entre los clústeres más cercanos debe ser mayor, lo que eventualmente asegurará que los clústeres estén lejos unos de otros.
- Además, el denominador debe ser mínimo para maximizar el índice Dunn. Aquí, estamos tomando el máximo de distancias intraclúster. Una vez más, la intuición es la misma aquí. La distancia máxima entre los centros de los clústeres y los puntos debe ser mínima, lo que eventualmente asegurará que los clústeres sean compactos.
Aplicaciones de clustering en el mundo real
La agrupación en clúster es una técnica ampliamente utilizada en la industria. En realidad, se está utilizando en casi todos los dominios, desde la banca hasta los motores de recomendaciones, desde la agrupación de documentos hasta la segmentación de imágenes.
Segmentación de clientes
Ya lo hemos comentado anteriormente, una de las aplicaciones más comunes de la agrupación en clúster es la segmentación de clientes. Y no se limita a la banca. Esta estrategia abarca todas las funciones, incluidas las telecomunicaciones, el comercio electrónico, los deportes, la publicidad, las ventas, etc.
Agrupación de documentos
Esta es otra aplicación común de la agrupación en clúster. Supongamos que tienes varios documentos y necesitas agrupar documentos similares. El clustering nos ayuda a agrupar estos documentos de manera que documentos similares estén en los mismos grupos.
Segmentación de imágenes
También podemos usar clustering para realizar la segmentación de imágenes. Aquí, intentamos juntar píxeles similares en la imagen. Podemos aplicar clustering para crear clústeres con píxeles similares en el mismo grupo.
Motores de recomendación
La agrupación en clúster también se puede utilizar en motores de recomendación. Digamos que quieres recomendar canciones a tus amigos. Puedes mirar las canciones que le gustan a esa persona y luego usar el clustering para encontrar canciones similares y finalmente recomendar las canciones más similares.
Estas son solo algunas aplicaciones, hay muchas más que, seguramente, diariamente las utilizas.
Esta es solo una breve explicación sobre clustering en las siguientes publicaciones estaremos explicando los algoritmos dentro de este tipo de Aprendizaje no Supervisado.
Con esto finalizamos la explicación de este contenido. Ya tienes las bases para entender el Clustering dentro del Aprendizaje no Supervisado, por lo tanto te dejo la siguiente pregunta, ¿Cuáles de las siguientes afirmaciones crees tú que sea cierta?
Opción 1: Un Clúster es la colección de objetos de datos que son similares entre sí dentro del mismo grupo.
Respuesta Correcta.
Opción 2: Los elementos de un mismo clúster deben estar lo más unidos posibles.
Respuesta Correcta.
Opción 3: De manera muy general, Spotify utiliza el clustering para recomendar las canciones a los usuarios.
Respuesta Correcta.




